State of GPT 2023
Andrej Karpathy, founding member of OpenAI, shared at Microsoft Build the pipeline used to train GPT.

In each of the stages of this pipeline, datasets, and algorithms are used, resulting in a trained model. The first stage consists of pretraining, where all the computational work is carried out using thousands of GPUs over months of training and millions of dollars.
Publicly available data is collected from websites like CommonCrawl (web scraper), Wikipedia, Github, among others.
Before inputting all this information to train the model, tokenization is performed, which is the native process that GPT uses. Tokenization converts the text into a sequence of integers. Approximately, 1 token is equivalent to 0.75 words in English.
If you find it difficult to understand, you can visit the OpenAI website for a clearer view: OpenAI Tokenizer.
During model training, the following aspects are considered:
- Vocabulary size.
- Context length.
- Parameters.
- Number of tokens used during training.
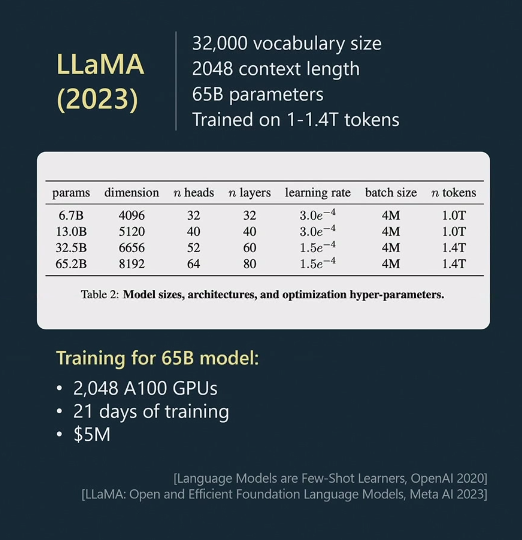
Image 2 represents the LLaMA model developed by Meta.
Afterward, the input given to the Transformer is organized into batches, which are essentially arrays with batch size and context length. What this Transformer does is try to predict the next word, as each token can only see tokens from the same batch and those before it. The New York Times trained a GPT model using Shakespeare's texts. For more information, check out: GPT from Scratch NYT.
As the model undergoes more training iterations, it becomes more accurate in predicting the next word.
After this process, we have our base model, which has been trained with a lot of information but of "low quality". That's why the next stage focuses on refining the model (fine-tuning) using less information but of "high quality".
One of the most important things Andrej mentions is that base models are not assistants; their main objective is to complete documents.

STF models are trained using a similar process, but with smaller datasets of higher quality, focused on answering questions and performing specific tasks.
After the second phase, we could consider the pipeline complete, although it's also possible to add additional stages using RLHF (Reinforcement Learning from Human Feedback). In the reward modeling stage, the results of the same prompt (completion) are compared and classified based on their quality.
In the last stage, once we have the completions classified for a specific prompt, the model can choose the best completion based on evaluation.
ChatGPT is an example of an RLHF model.
RLHF models tend to generate results with less variation, whereas base models tend to be more diverse, which can be useful in certain contexts.
In the second part of the talk, Andrej shared several tips for achieving better results using LLMs:
- Sometimes, LLMs can have bad luck and produce a poor sample, so it's recommended to make multiple attempts.
- Ask reflective questions to LLMs; they know when they make mistakes.
- LLMs don't aim for conventional success; their primary objective is to imitate the training datasets. If you want them to succeed in a specific sense, you must formulate your questions in a way that clearly indicates that goal. For example, "You are an expert developer with an IQ of 120." However, it's important to be realistic to avoid the LLMs resorting to fictional sources like sci-fi.

If you have 45 minutes, you can watch the full talk here: Microsoft Build 2023 Andrej Karpathy